Coroutines introduction
And so it’s happened. After a long time of doubts, opposition, and preparation of this feature, WG21 agreed on how the coroutines should look like, and coroutines will likely come into C++ 20. Since it’s a significant feature, I think it’s good to start preparing and learning this now (remember there are also modules, concepts, and ranges in the to learn list ).
There were lots of people opposing this feature. Main complaints were regarding the hardness to understand, lots of customisation points, and possibly not optimal performance due to possibly unoptimised dynamic memory allocations ( possibly 😉 ).
There were even parallel attempts to the accepted TS (officially published Technical Specifications) to create another coroutines mechanism. Coroutines, we will be discussing here are the ones described in the TS (Technical Specification), and this is the document to be merged with the IS (International Standard). The alternative, on the other hand, was created by Google. Google’s approach, after all, turned out to also suffer from numerous issues, which were not trivial to solve, often requiring strange additional C++ features.
The final conclusion was to accept the coroutines by Microsoft (the authors of the TS). And this is what we are going to talk about in this post. So let’s start with…
What are the coroutines?
The coroutines already exist in many programming languages, may it be Python or C#. Coroutines provide one more way to create asynchronous code. How this way differs from threads and why do we need a dedicated language feature for coroutines and finally how we can benefit will be explained in this section.
There is lots of misunderstanding regarding what the coroutine is. Depending on the environment in which they are used they might be called:
- stackless coroutines
- stackful coroutines
- green threads
- fibers
- goroutines
Good news is that stackful coroutines, green threads, fibres, goroutines are the same thing (sometimes used differently). We will refer to them later on as the fibres or stackful coroutines. But there is something special about the stackless coroutines, which is the main subject of this series of posts (you can expect soon more posts about the coroutines and how to use them).
To understand the coroutines and get some intuition about them, we will first have a brief look at the functions and (what we might call) “their API”. The standard way of their usage is to simply call them and wait until they finish:
void foo(){
return; //here we exit the function
}
foo(); //here we call/start the functionAfter we once called the function, there is no way we can suspend it or resume it. The only operations on the functions we can perform are start and finish. Once the function is started, we must wait until it’s finished. If we call the function again, it begins execution from it’s beginning.
The situation with the coroutines is different. You can not only start and stop it but also suspend and resume it. It is still different than the kernel’s thread because coroutines are not preemptive by themselves (the coroutines on the other hand usually belong to the thread, which is preemptive). To understand it let’s have a look at the generator defined in the python. Even though the Python world calls this generator it would be called coroutine in the C++ language. The example is taken from this website :
def generate_nums():
num = 0
while True:
yield num
num = num + 1
nums = generate_nums()
for x in nums:
print(x)
if x > 9:
breakThe way this code works is that the call to the generate_nums function creates a coroutine object. Each time we iterate over the coroutine object the coroutine is resumed and suspends itself once the yield keyword is encountered, returning next integer in the sequence (the for loop is syntactic sugar for the next function call, which resumes the coroutine). The code finishes the loop on encountering the break statement. In this case, the coroutine never ends, but it’s easy to imagine the situation in which coroutine reaches its end and finishes. So now we can see, that this kind of coroutine can be started, suspended, resumed and finally finished [Note: there is also create and destroy operation in the C++ language, but it’s not needed to get the intuition of the coroutine]
Coroutines as the library.
So you now have the intuition of what coroutines are. You know there already are libraries for creating fibres objects. The question is then why do we need to have a dedicated language feature and not just library, that would enable the use of the coroutines.
This tries to answer this question and show you the difference between stackful and stackless coroutines. The difference is the key to understand the coroutine language feature.
Stackful coroutines
So first let’s talk about what are stackful coroutines, how they work, and why they can be implemented as a library. They might be easier to be explained since those are built similarly to the threads.
Fibers or stackful coroutines are, a separate stack, that can be used to process function calls. To understand how exactly this kind of coroutine works, we will have a brief look into function frames and function calls from the low-level point of view. But first, let’s have a look at the properties of the fibers.
- they have their own stack,
- the lifetime of the fibers is independent of the code that called it (usually they can have user-defined scheduler),
- fibers can be detached from one thread and attached to another,
- cooperative scheduling (fiber must decide to switch to another fiber/scheduler),
- cannot run simultaneously on the same thread.
Implications for the mentioned properties are following:
- fibre’s context switching must be performed by the fibres’ user, not the OS (OS still can dispossess the fibre by dispossessing the thread on which it runs),
- No real data races occur between two fibres running on the same thread since only one can be active,
- fibre developer must know when it’s a proper place and time to give computation power back to the possible scheduler or callee.
- I/O operations in fibre should be asynchronous so that other fibres can do their job without blocking one another.
Let’s now explain how fibres work in the detail starting from the explanation of what is stack doing for the function calls.
So the stack is a contiguous block of the memory, that is needed to store the local variables and function arguments. But what is even more important, after each function call (with few exceptions) additional information is put on the stack to let know the called function how to return to the callee and restore the processor registers.
Some of the registers have a particular purpose and are saved on the stack on function calls. Those registers (in case of the ARM architecture) are:
- SP – stack pointer
- LR – link register
- PC – program counter
A stack pointer is a register that holds the address of the beginning of the stack, that belongs to the current function call. Thanks to this value it’s easy to refer to the arguments and local variables, that are saved on the stack.
Link register is very important during the function calls. It stores the return address (address to the callee) where there is a code to be executed after the current function execution is over. When the function is called the PC is saved to the LR. When the function returns the PC is restored using the LR.
Program counter is the address of currently executed instruction.
Every time when a function is called the link register is saved, so that function knows where to return after it’s finished.
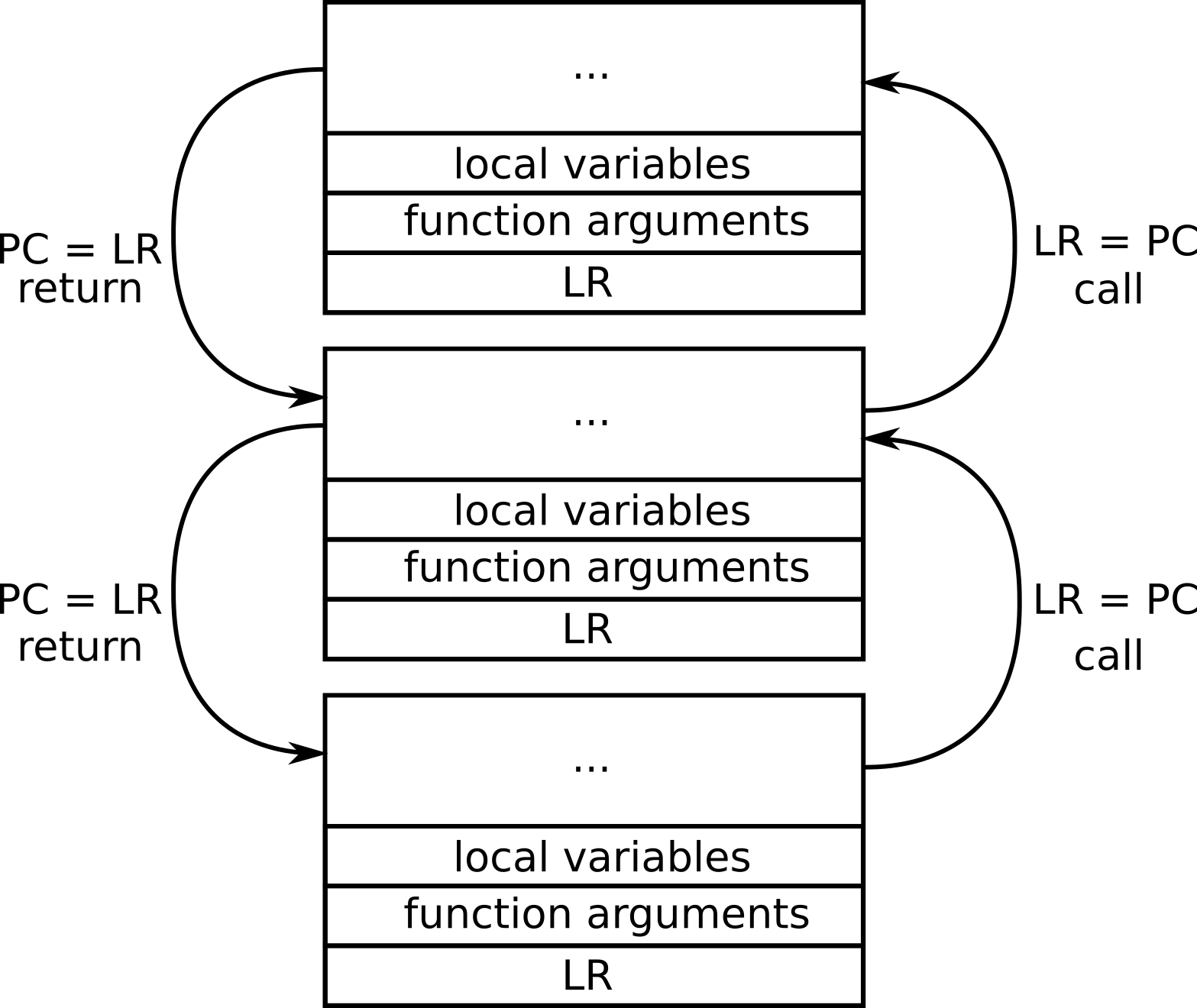
When the stackful coroutine gets executed, the called functions use the previously allocated stack to store its arguments and local variables. Because function calls store all the information on the stack for the stackful coroutine, fibre might suspend its execution in any function that gets called in the coroutine.
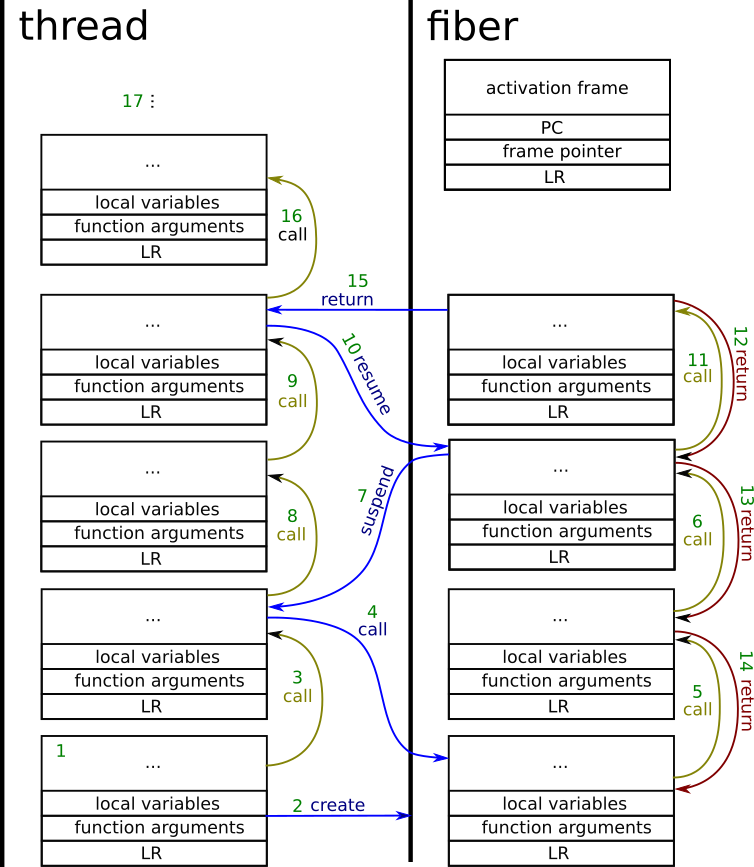
Let’s now have a look at what is going on in the picture above. First of all, threads and fibers have their own separate stacks. The green numbers are the ordering number in which actions happen
- The regular function call inside the thread. Performs stack allocation.
- The function creates the fibre object. In result, the stack for the fibre gets allocated. Creating the fibre does not necessarily mean that it gets immediately executed. Also, the activation frame gets allocated. The data in the activation frame is set in such a way, that saving its content to the processor’s registers will cause the context switch to the fibre stack.
- Regular function call.
- Coroutine call. Processor’s registers are set to the content of the activation frame.
- Regular function call inside the coroutine.
- Regular function call inside the coroutine.
- Coroutine suspends. The activation frame content gets updated, and processor’s registers are set, so that context returns to the thread’s stack.
- Regular function call inside the thread.
- Regular function call inside the thread.
- Resuming the coroutine – similar thing happens during the coroutine call. The activation frame remembers the state of processor’s registers inside the coroutine, which were set during the coroutine suspension.
- Regular function call inside the coroutine. Function frame allocated in the coroutine’s stack.
- Some simplification on the image is done. What happens now is that coroutine ends, and the stack is unwinded. But the return from the coroutine in fact happens from the bottom (not top) function.
- Regular function return as above.
- Regular function return.
- Coroutine return. The coroutine’s stack is empty. The context is switched back to the thread. From now on, the fibre cannot be resumed.
- A regular function call in the thread’s context.
- Later on, functions can continue the operation or finish, so that finally the stack gets unwinded.
In the case of the stackful coroutines, there is no need for a dedicated language feature to use them. Whole stackful coroutines could be just implemented with the help of the library and there are already libraries designed to do this:
- https://swtch.com/libtask/
- https://code.google.com/archive/p/libconcurrency/
- https://www.boost.org Boost.Fiber
- https://www.boost.org Boost.Coroutine
Of those mentioned only Boost is C++ library, as other ones are just C ones.
The details of how the libraries work can be seen in the documentation. But basically, all of those libraries will be able to create the separate stack for the fiber and will provide the possibility to resume (from the caller) and suspend (from inside) the coroutine.
Let’s have a look of the Boost.Fiber example:
#include <cstdlib>
#include <iostream>
#include <memory>
#include <string>
#include <thread>
#include <boost/intrusive_ptr.hpp>
#include <boost/fiber/all.hpp>
inline
void fn( std::string const& str, int n) {
for ( int i = 0; i < n; ++i) {
std::cout << i << ": " << str << std::endl;
boost::this_fiber::yield();
}
}
int main() {
try {
boost::fibers::fiber f1( fn, "abc", 5);
std::cerr << "f1 : " << f1.get_id() << std::endl;
f1.join();
std::cout << "done." << std::endl;
return EXIT_SUCCESS;
} catch ( std::exception const& e) {
std::cerr << "exception: " << e.what() << std::endl;
} catch (...) {
std::cerr << "unhandled exception" << std::endl;
}
return EXIT_FAILURE;
}In the case of Boost.Fiber the library has a built-in scheduler for the coroutines. All fibres get executed in the same thread. Because coroutines scheduling is cooperative, the fibre needs to decide when to give control back to the scheduler. In the example, it happens on the call to the yield function, which suspends the coroutine.
Since there is no other fibre, the fibre’s scheduler always decides to resume the coroutine.
Stackless coroutines
Stackless coroutines have a little bit different properties to the stackful ones. The main characteristics, however, remain as stackless coroutines still can be started, and after they suspend themselves, they can be resumed. We will call stackless coroutines from now on simply coroutines. This is the type of coroutines we are likely to find in the C++20.
Just to make simillar list of coroutines properties, coroutines can:
- Coroutines are strongly connected to the callers – call to the coroutine transfers execution to the coroutine and yielding from the coroutine comes back to its caller.
- Stackful coroutines live as long as their stack. Stackless coroutines live as long as their object.
In case of the stackless coroutines, however, there is no need to allocate the whole stack. They are far less memory consuming, but they have got some limitations because of that.
So first of all, if they do not allocate the memory for the stack, then how do they work? Where goes all the data meant to be stored on the stack in case of the stackful coroutines? The answer is: on the caller’s stack.
The secret of stackless coroutines is that they can suspend themselves only from the top-level function. For all other functions their data is allocated on the callee stack, so all functions called from the coroutine must finish before suspending the coroutine. All the data that coroutine needs to preserve its state is allocated dynamically on the heap. This usually takes a couple of local variables and arguments, which is far smaller in size than the whole stack allocated in advance.
Let’s have a look on how stackless coroutines work:
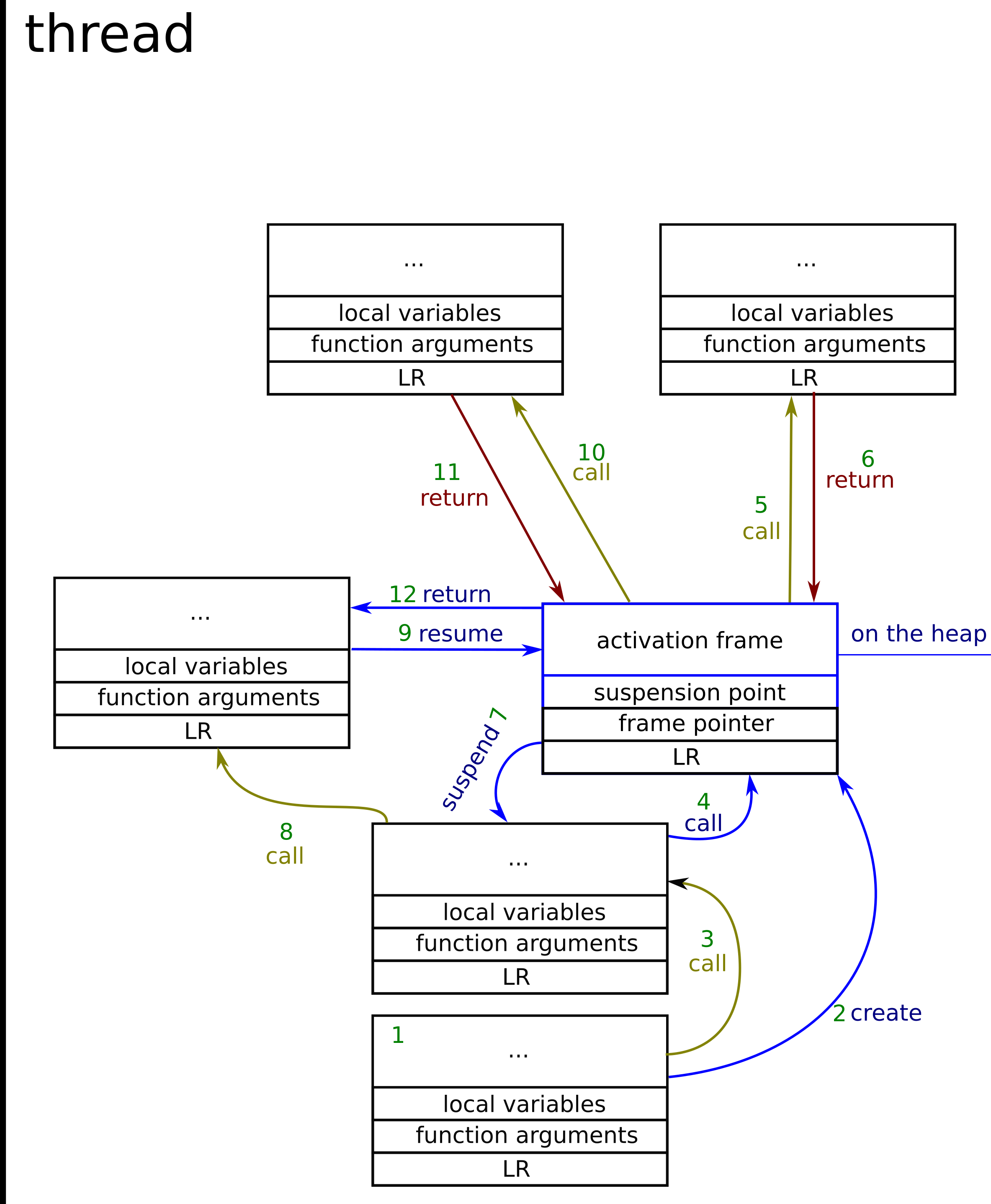
Now as we can see, there is only one stack – this is threads main stack. Let’s follow step by step what is going on in the picture. (the coroutine activation frame is in two colors – black is what is stored on the stack and blue is what is stored on the heap).
- Regular function call, which frame is stored on the stack
- The function creates the coroutine. This means allocating the activation frame somewhere on the heap.
- Regular function call.
- Coroutine call. The body of the coroutine gets allocated on the usual stack. And program flow is the same as in case of normal function.
- Regular function call from the coroutine. Again everything is still on the stack. [Note: coroutine could not be suspended from this point, as it’s not the top-level function of the coroutine)
- Function returns, to the coroutine’s top-level function [Note coroutine can now suspend itself.]
- Coroutine suspends – All the data needed to be preserved across the coroutines calls are put into the activation frame.
- Regular function call
- Coroutine resumed – this happens as the regular function call, but with the jump to the previous suspension point + restoration of the variables state from the activation frame.
- Function call as in point 5.
- Function return as in point 6.
- Coroutine return. Cannot resume the coroutine from now on
So as we can see there is far fewer data needed to be remembered across the coroutine suspensions and resumes, but coroutine can suspend and return from itself only from the top level function. All the function and coroutine calls happen in the same way, in the case of the coroutine, however, some additional data needs to be preserved across the calls to know how to jump to the suspension point and restore the state of the local variables. Besides, there is no difference between the function frame and coroutine frame.
A coroutine can also call other coroutines (which is not shown in the example). In case of the stackless coroutines, each call to one will end up allocating new space for new coroutines data (multiple calls to the coroutines might cause various dynamic memory allocations).
The reason why coroutines need to have a dedicated language feature is that the compiler needs to decide, which variables describe the state of the coroutine and create boilerplate code for jumps to the suspension points.
Coroutines use cases
The coroutines could be used in the exact same way as the coroutines in other languages. Coroutine will simplify writing:
- generators
- asynchronous I/O code
- lazy computations
- event driven applications
Summary
What I would like you to know after reading this article is:
- why do we need a dedicated language feature for coroutines
- what is the difference between the stackful and stackless coroutines
- why do we need coroutines for
I hope that this article helped you in understanding those topics and was interesting enough to wait for more posts on coroutines – this time with code examples in C++!